Feature
Research Report
Building the Case for Modern Public Sector Messaging


While there is much research to chronicle how chaotic the management of information is in the enterprise at the moment, there is little enough in way of practical advice, or even tools, to suggest a way to tame unruly content. However, with Project Barcelona, Microsoft aims to provide an information crawler that will go into your network and map your dataflows and metadata.
Recently, we have seen in the AIIM State of the ECM Industry report that content chaos remains a challenge for most, and we have also seen advice from Forrester on how to build content strategies. But if you don’t know what you have, or, even worse, know what you have but don’t know where to find it, no amount of strategizing is going to help.
This is where this new project comes in, although we probably won’t even have a release roadmap until later in the summer. The concept and project, led by Microsoft researcher Andrew Conrad, appears to be well on the way, and, on the face of it, heading in a direction many enterprises will welcome.
But let’s start at the beginning. In a recent blog post for the Barcelona Project, Conrad outlined where the idea comes from and how they the team is approaching the problem.
To understand the way they are thinking, they have drawn an analogy between the web, with its vast decentralized topology of sites and services, and an enterprise, where the information that is being used is increasing at an exponential rate.
It is here that Conrad has identified the core of the problem. While we all know that this is happening in the enterprise, on the web, numerous complex tools for navigating and understanding it have developed as the web has developed.
As a result, the information and content that we see on the web is, arguably, under control; under control, that is, in comparison to information and content in the enterprise.
And behind it all, one of the tools that gives it order is web crawlers that are constantly crawling around the web, indexing content, without anyone having to understand the technology behind it.
Few, if any, such tools exist for the enterprise, and it is this that Conrad and his jolly band aim to change.
Historically, in the enterprise, this problem has evolved because, in the early days, data was stored, for the most part, in relational databases with the IT department controlling most of the data, simply because the skills required in managing these went beyond those of your average IT worker.
That, however, in recent times, has changed, Conrad argues, so that:
While this has led to productivity gains in most enterprise -- assuming, again, it is possible to locate data -- it has made life more difficult for DBAs (Database Administrators) and ELTs (Extract, Load Transform Administrators), or the people who pull data out of one database and place it into another.
Add into the mix, Conrad says, that unless an information worker knows a bit about SQL, it is unlikely that they would be able to work out, for example, where information in a SharePoint spreadsheet that has been fed into the silo they are working on comes from. Does anyone really want to use information, the origin of which is unknown?
The problems with this, he says, are enormous. In the case of a DBA who wants to do some housecleaning and change the data type of a column, for example, within the server there are tools for figuring out what will break, but what about outside the database server? Does the DBA really know what is going to break?
After asking DBAs how they deal with this the most common answer was:
Not an acceptable solution, he argues.
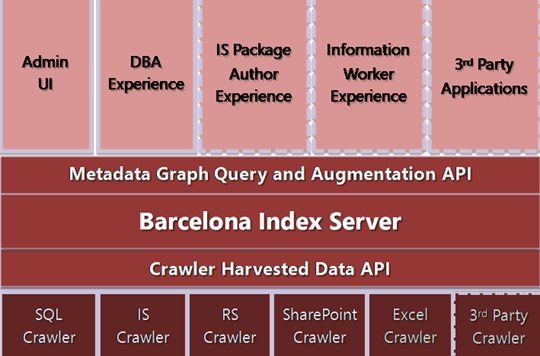
And this is where Project Barcelona comes in. What they are trying to do is build a map of enterprise technology with few setup or administration tasks for the users.
The idea is that the crawlers that are finally developed will be pointed at enterprise systems, which will then map the enterprise's metadata and the dataflows between systems and applications. The envisioned products will consist of three components:
Moving into the future, Conrad envisages a developer solution that goes beyond the initial DBA and ETL iteration. The base for the platform will be open from the start, so he sees a situation where developers will be able to plug in their own crawlers or metadata providers.
Also, because it will support metadata augmentation and have rich annotation support, it will enable users of the system to use the crawlers and Index servers that they haven’t thought of yet.
On a final note for now, Conrad says that, because the project is consumer-driven, they will be looking to work with the wider community on the design and development of features, before finalizing the design and feature set with the help of community feedback.
This is an ongoing project and will develop over the course of the next few months. If you are interested in more, check out the blog post, which he says will contain updates about project progress and discussions about developments as they happen