Feature
Research Report
Building the Case for Modern Public Sector Messaging


![filetekLogo[1].gif](/-/media/0f6a35970a1b472791737d9c32ecdf8d.gif)
What this version of FileTek will do is to extend existing enterprise content management policies and go rummaging through desktops where FileTek reckons up to 80% of this content resides.
What’s even better the company says, is that you don’t have to be working with a FileTek product to use it as it can be easily integrated with the majority of large ECM systems, including SharePoint, IBM Content Manager, Open Text Livelink and EMC.
And just in case you thought you could stuff some content into e-mails to avoid classification, Trusted Edge can also categorize and tag e-mail information to an e-mail archival solution such as Symantec Enterprise Vault.
Any company that works with eDiscovery or has to manage compliance issues on a weekly basis will know how difficult it can be to find all the information that is floating around a company’s content system.
This is not a deliberate attempt by users to keep information out of the system, but rather a lack of awareness of what constitutes a business record according to criteria established by the given enterprise.
FileTek estimates that end users create up to 80% of content on a daily basis and that 20% of this ends up as business records, with the other 80% floating around file shares, desktops or more commonly, remote laptops.
And this is where Trusted Edge comes in. Trusted Edge was a company that developed policy-driven desktop classification, capture and disposal solutions for unstructured data such as e-mail, desktop documents and files.
That is until June 2007 when FileTek moved in and took it over. FileTek produces large-scale data management and information governance solution for Global 200 companies.
With the acquisition of Trusted Edge it added another string to its document management bow and at the time said it would be developing the Trusted Edge product to tackle unstructured content. No doubt this was with an eye towards the growing compliance and eDiscovery market.
Over two years later we now have v4.0.
While some users may not like the extension of ECM classifications to content that has not been specifically placed in a repository, the financial implications of not keeping an eye on what content is available and where it is located in a given system should make sense to everyone.
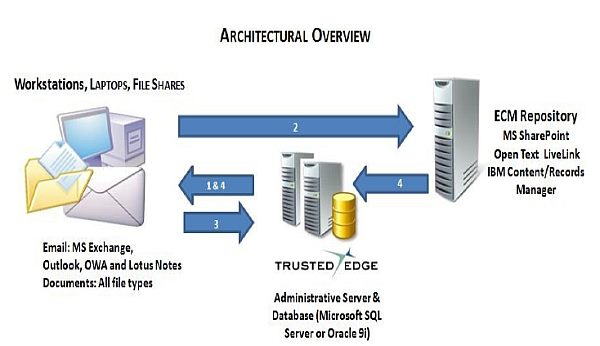
The company has made it clear that the extension of this system is transparent wherever it is installed. And while it will probably catch everything that is lying around, its primary purpose is to collect, file, hold or dispose of both new -- and more importantly -- legacy documents that may have avoided classification to date.
This is specifically designed to find information at “the edge of networks”, the company says, and to classify all this information, including email content, based on content categories, pattern searches and scanning either automatically for simple classifications, or manually for more complex or specific tasks.
Features include:
With these, Trusted Edge monitors end-user desktops in real time for any new or modified emails and documents.
When a qualified document or email is identified, the client applies capture rules appropriate for that document or email type.