Feature
Research Report
Building the Case for Modern Public Sector Messaging



It was only a matter of time before a big data vendor explicitly focused on content management. Much of the growth in data size leading to the moniker big data is unstructured content that is challenging to manage in traditional relational repositories. New open source big data entrant Lily builds upon Apache Software Foundation top level Hadoop, HBase and SOLR projects. It wraps these data technologies in an integrated open source platform that includes storage, indexing and search and is more suitable for corporate environments than the native Apache stack, which requires technical expertise, lots of reading, a few forum visits, luck and a sprinkle of black magic to get running.
Interestingly, in addition to Lily’s core features, the platform works with Cloudera's Distribution for Hadoop, the current leader in the Hadoop market. Lilly is certified CDH-compatible.
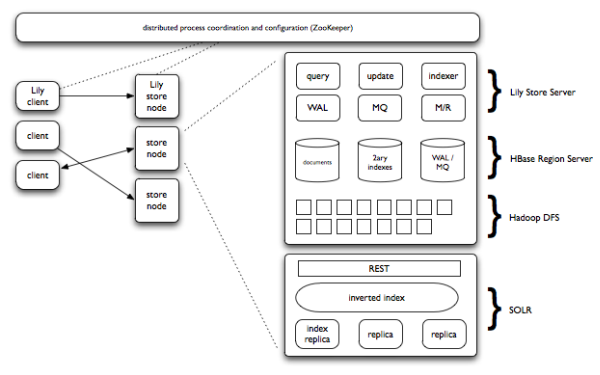
Lily has a distributed architecture that supports functional layering, scalability and fault tolerance with multiple nodes performing different functions and multiple nodes performing the same function. Lily leverages Apache HBase, based on Google’s BigTable, for storage. HBase handles failing nodes. And, although HBase does not really have support for querying or transactions, it provides storage for billions of rows and large amounts of columns of data by adding more hardware.
Lily's repository provides basic record management for content management applications. The platform supports rich field types, versioning and a flexible schema. Unlike many content repositories, such as Java Content Repository (JCR), Lily’s repository does not use a hierarchical model. Hierarchical models require users to define content organization and decide where in the hierarchy to store each entity. The Lily repository is one big bag of records, and it does not have tables, either -- there is just one set of records, each uniquely identified by an ID. This provides users tremendous flexibility in how content is persisted. Additionally, Lily provides Java and REST APIs for creating, reading and managing data.
In relational databases, transactions ensure that multiple actions happen as an atomic operation -- everything fails or succeeds together. However, HBase does not require transactions, atomicity or rollbacks. Lily uses a write-ahead-log (WAL). Before performing any operation on the repository, Lily writes its intention to WAL; when the repository is updated, it confirms to the WAL. If at any point the process fails, the WAL is checked and any remaining actions are performed.
Lily integrated with Apache SOLR, an open source enterprise search solution based on Lucene. Lily enhances SOLR by automating index maintenance, but does not handicap the platform. Lily leaves all native SOLR features exposed to users.
Lily has released details on its next two releases. Lily plans to develop into an integrated business intelligence platform with built-in metrics on data usage and audience data. Lily 1.5 will include built-in attention data collection and analytics. The company plans to add real-time content recommendations based on attention data and user-provided domain knowledge in Lily 2.0. Lily also plans on offering a cloud-based software-as-a-service.
The product is available now at http://www.lilyproject.org/.