Feature
Research Report
Building the Case for Modern Public Sector Messaging


Amazon announced two more EC2 instance types at its first ever partner conference reInvent this week, and also showed off a new analytics tool called AWS Data Pipeline.
During the Amazon re:Invent day two keynote address, Amazon.com CTO Werner Vogels shared his 21st century application commandments and announced the new releases from Amazon Web Services.
Vogels avoided going old testament on the Las Vegas conference crowd, but his keys to the next generation of cloud aware applications were prescriptive, not just meant to convert people to AWS. Although that is no doubt part of his job, he chose his words carefully making sure to tie business processes to every step of modern software development.
Twenty-first century cloud architectures should be controllable, resilient, adaptive and data driven, Vogels said. Old world constraints have held businesses back for too long because they forced companies to focus on resources instead of focus on business and customers. Automating business processes is a big part of that, and with the advent of the cloud, massive volumes of data can be computed to that end.
Amazon's new Cluster High Memory and High Storage Instances are far larger than Google's new Compute Engine instances that the company announced just before re:Invent began this week. The two new instances add to Amazon's already dominating lineup, and they are meant to help businesses analyze the critical data they need to be successful.

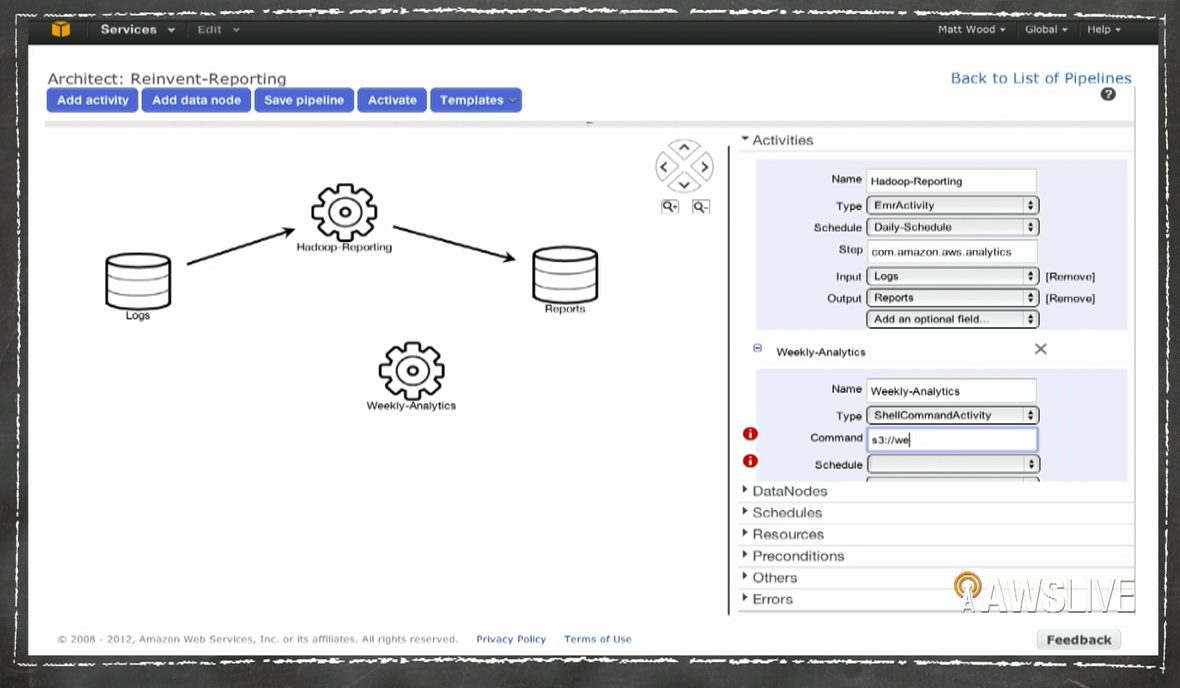
AWS Data Pipeline is also aptly named because it is meant to help businesses automate analytics, while at the same time moving data between stores. This goes along with what Vogels preached during his presentation. The cloud allows companies the freedom to do so many things in an unconstrained, business driven way, nothing should be left out.
Because all the compute power companies need is included on a per-usage basis, there is no need not to put as much as possible into the cloud, Vogels said. AWS Data Pipeline helps companies do this by integrating Dynamo database data into Amazon S3 stores automatically, for example. It uses drag and drop to insert data sources, and there are templates for pre-made implementation examples.
Running daily reports using data from one store and then adding that report to another store is just one way to use the new integration system. It can use parameters to run reports only after a certain number of days or amount of data collected, whatever kinds of information needed.
Is Amazon the new king of data? In a way yes, because the combined power of its compute instances simply is unmatched by anyone. Perhaps that makes the company vulnerable, but with no shortage of large companies moving to the cloud, or at this point, being founded in the cloud (think Pinterest), there is a short list of competitors.