Feature
Research Report
Building the Case for Modern Public Sector Messaging


Advances in an artificial intelligence technique known as deep learning are helping companies like Microsoft and Nuance create powerful speech analytics and voice recognition software at a much quicker pace than ever before.
Deep learning is a system of pattern recognition modeled after the ability of the human brain to gather information and learn from it. Microsoft Chief Research Officer Richard Rashid gave a rousing demonstration of the technology at a recent conference in China.
Rashid lectured to an audience while a software system showed his words on a screen above his head. The speech recognition program then translated the words into Chinese, and even spoke the words in Rashid's own voice, according to the New York Times' John Markoff.
Rashid does not speak Chinese. How did Microsoft teach a computer to simulate a person's voice in a language that a person had never spoken? The easy way to do it would be simply to have Rashid actually speak a group of phrases in Chinese, record it, and then use a computer to extrapolate that pre recorded sound into whatever phrase needed to be translated.
That's a neat trick, but hardly practical. In order to teach a computer how to do something like this, breakthroughs in things like deep learning are required. Microsoft has a renowned research division, and while we don't know exactly how far it has gone into this particular branch of artificial intelligence technology, we did track down the secret to how Rashid made headlines in the Times last week.
Microsoft calls it trajectory tiling -- the entire process was laid out in a March 2012 presentation by Rashid at the TechFest conference, a celebration of 20 years of Microsoft research. It should come as no surprise then that Rashid has been in charge of this Microsoft segment during the entirety of those two decades. In fact, he was hired away from a Carnegie Mellon professor's job specifically to help start up Microsoft Research.
Increasingly, the virtual and the physical worlds are merging", Rashid said at TechFest 2012 in March. "Part of this is happening because we are giving computers the same senses we have. We are giving them the ability to see, we are giving them the ability to hear and to understand."
Dedicated to basic computer science research for the last 20 years, Rashid said he is confident his company is changing the kinds of applications it can build and how we interact with computers.
Frank Soong, principal researcher, Microsoft Research Asia did the trajectory tiling demonstration at TechFest 2012. He called it trained multilingual text to speech. Instead of starting with Rashid's own voice reciting various Chinese phrases like in the above example, a reference speaker is recorded instead.
That is, a Chinese voice is recorded as a baseline. This voice is then used to construct the underlying parameter trajectory, the fundamental frequency, the gain and the loudness of the targeted translation. In this case it's Chinese, but the same method would be used for whatever language is needed.
Once the baseline is established, the two voices (reference speaker and target person's voice) are warped or equalized. The trajectory is warped towards the English speaker, in this case.

This is where the voice sausage is made. The English speaking person's voice database is broken into tiny pieces, in this case 5 milliseconds. Then the engineers construct all the pieces which are closest to the trajectory of the warped Chinese sentence. This sausage like network is formed, and then within that network, they find the best concatenation of all the sequence of tiles.
This can be used to form a Chinese language sentence in the English speaking person's own voice. More sentences can be built from there, and together they form training sentences for the Chinese text to speech program. With this program in hand, whenever the English speaking person needs something translated, it can be spoken by the computer in that person's voice.
At TechFest 2012, however, there was an added step Rashid didn't show off at his now famous lecture in China. Researchers built a virtual talking head simulation of Craig Mundie, head of research and strategy (and Rashid's boss), and used his voice to show off the software.
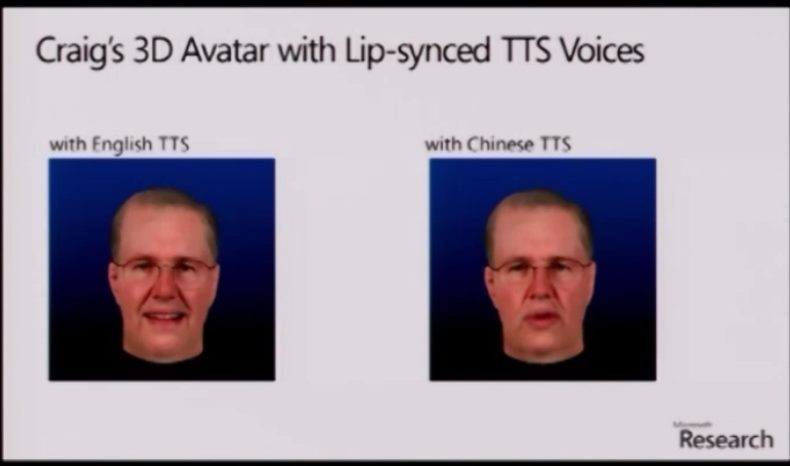
So in this image, Mundie's voice and image are computer generated, but very much based on real data from the man himself. None of this would be possible without deep learning. The problem is, the system is still far from perfect, a problem voice recognition and interactive voice response (IVR) technology has had since the 1970s.
While Microsoft and Nuance, the technology behind Apple's Siri digital assistant, are getting better at speech recognition and machine learning at a faster pace, the enterprise still has to rely on a bevy of less sci fi-y tools.
Aberdeen Group has a new speech analytics buyers guide out in November, and it focuses on things like improving financial returns at call centers, for example. The report found speech to text in particular is "especially helpful for contact centers serving a wide range of demographics as it helps them update their vocabulary with words and phrases used more widely by certain demographic groups."
We spoke to Aberdeen researcher Omer Minkara who wrote the report, and he said revolutionizing customer interactions through voice recognition could take another 5-10 years.
"Despite the clear benefits of helping businesses personalize customer interactions, both consumers and businesses find many gaps and inaccuracies in real-life use cases of these tools," Minkara said in an email.
"This use case information needs to be compiled, analyzed and built into refinement of next generation speech recognition tools in order to improve the accuracy and timeliness of these tools within future customer interaction scenarios."