Editorial
eBook
Web Marketing Moneyball: How Web Operations Drive Marketing ROI

By now, you’re probably familiar with virtualization, and it has probably been defined for you as the staging of software assets on a software-based platform spread across multiple servers, engineered to look to those assets like a hardware-based platform.
That’s certainly what virtualization has been for most data centers. The change for some has already come in the form of containerization, a new form of virtualized workload made popular by Docker.
In Part 1 of this series, CMSWire introduced you to three methodologies for maintaining virtualized containers, each of which is being advanced as a candidate for the de facto method for container orchestration.
Part 2 shows you four alternative methods being advanced as part of the emerging containerization market.
Any one of these seven methods may be considered analogous to using VMware’s vSphere or Citrix’ XenServer to manage conventional virtual machines (VMs).
That there are (at least) seven methods for managing containerized workloads speaks both to the vigor of the emerging containerization market, and to the lack of certainty at this early stage as to how this technology should best be put to use, especially in enterprises where scaling (up or down) has not yet become an issue.
In systems comprised mainly of open source components that were not designed with one another necessarily in mind, the way administrators monitor how those components behave is through the logs they produce. We’ve already seen how big data technologies have been put to use in making server logs useful, by treating them like live data streams and mathematically reducing them, using services such as Apache Kafka.
Sumo Logic applies this approach to container environments that produce server logs, with one of the first machine learning-based analytics tools dedicated to Docker. The basic theory behind it, as Sumo’s director of product management, Sahir Azam, told us in June, is that containerization is so new that the concepts of “good behavior” and “bad behavior” have yet to flesh themselves out in production environments.

“This uses multi-dimensional statistical analysis to build a dynamic threshold around the data,” explained Azam, “that understands time-of-day, seasonality, and the like, but only alerts when there are true statistical deviations. And that makes the alerts much more actionable, and much more accurate.”
Some would argue that an analytics-based system such as Sumo Logic does not qualify as true orchestration, because it omits the automated facilities for actually submitting containers to private or public repositories, and deploying them to live servers.
On the other hand, other orchestration systems such as Kubernetes do not directly monitor behavior. And systems that give more graphical insight as to the running state of containers or clusters, such as Mesosphere, are not measuring the logs to detect varying levels of throughput or sources of traffic bottlenecks.
So from an analytics expert’s point of view, the more native orchestration environments are not providing true orchestration.
IT departments that are more accustomed to vSphere, and VM administrative systems like it, are looking for the container-based equivalent of the application lifecycle manager. In fact, some vendors have advanced the notion that, in the absence of a substitute for conventional ALM, containerization is unworkable in practice.
Typically, a container (such as a Docker container) is not meant to be a miniature, or shrink-wrapped, virtual machine. In orchestration systems such as Mesosphere, a container may act as a server that answers requests for a specific function. The more requests there are for that function, the more replication that can be applied to that container to respond to them.
This has led to a metaphor in the industry where containers are treated more like cattle than pets. You raise them, you feed them well, but you expect them to not hang around for very long.
If, indeed, instances of containers are destined for the slaughter, if you will, once their useful functions have been fulfilled, then you could argue that a lifecycle management system runs contrary to the whole purpose of containerization. Vendors of lifecycle management systems for containers may actually agree.
Others, such as HashiCorp, argue that while container architecture may eventually alter the environments of data centers, it won’t happen overnight. New containerized applications must share the data center with conventional VMs.
HashiCorp positions its Atlas infrastructure management system as a kind of bridge between the two worlds, monitoring the health of the overall system, including how both VMs and containers contribute to it.

Unlike the typical container orchestration system that was developed with the notion that the developer would be the one operating it, Atlas is geared for the IT administrator. Its goal (and admittedly, it may take a few more iterations before it gets there) is to eliminate the complexities of administering virtual workloads to such an extent that admins need not consider whether an application workload is a VM or a container.
VMware might be the company that stands the most to lose as containers start to replace VMs. To stave off a VM exodus, VMware is now professing the virtues of a completely new infrastructure management framework that incorporates all kinds of virtual workloads, including containers.
The company calls this new framework “microsegmentation,” and argues that while containerization has its benefits, we can’t go on pretending that it will replace existing architectures (thus creating a world without VMware).
Next week, during the company’s VMworld conference, expect to see more about what’s effectively a hybrid environment, a “single pane of glass” where administrators have full oversight over all virtual workloads.
VMware does have a point, though: However you may categorize the “critical mass” that Docker-style architecture may have reached in certain classes of high-volume data centers, it cannot and will not upend enterprises’ existing investments in business applications.
A company called New Relic has already established itself in the application performance monitoring space, as my friend and colleague Dee-Ann LeBlanc explained for CMSWire in 2010. It produces a system with which a monitoring agent is injected into server applications, monitoring for traffic, throughput, and behavior, and reporting that data periodically to a central server.
New Relic’s APM has the virtue of not needing significant retooling for containerized environments. Its agent is installed as a library inside the application itself. Developers make space for it inside their Java, Python, PHP, or Node.js source code.
So developers don’t actually have to do anything (much) differently than they have with New Relic up to now. Its agent is integrated into the software, and interacts over the network with the company’s performance monitor, which runs from a browser.
As with any library code injected into a server program that runs over a network, there is always some concern over the extent to which the injected code negatively impacts performance. Think of it as the data center equivalent of Heisenberg’s “observer effect” in physics.
(In practice, though, this performance impact is negligible, at best, and certainly can be mitigated by way of the tweaks developers and admins can make, once they have greater visibility into the performance of their applications.)
A new company called Sysdig aims to overcome what impact there may be, at least with respect to containers. Rather than attaching a library to source code, Sysdig has admins inject a separate container into the environment.
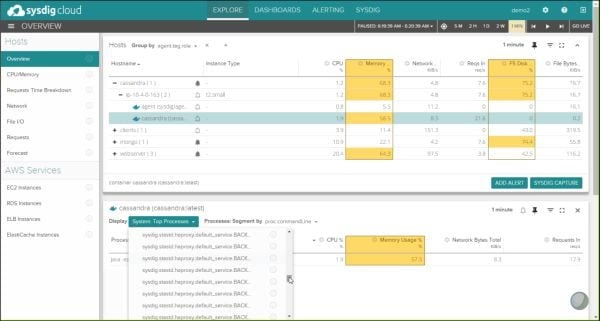
That container interacts with all the others by way of the internal network that connects them to one another (containers use software-defined, IP-based subnets). Sysdig’s alternative has the virtue of eliminating the need to alter source code, though theoretically it could move the point of performance impact from the apps themselves to their environment.
(Again, even if that performance impact is negligible, the whole point of monitoring at this level is to give information workers the tools and incentive they need to mitigate it.)
One unexpected side-benefit of Sysdig’s choice of tack is how it provides a live, zoomable map of the running status of all containers in a data center, as though they were individual machines with coordinates on an Internet Protocol grid.
The first successful cloud-based services, even before Amazon began selling virtual servers on a metered basis, were language platforms. PaaS platforms, such as Microsoft’s Azure and Salesforce’s Heroku, gave rise to the idea that applications could be deployed more readily and more efficiently if some or all of those platforms resided on-premise.
A hybrid PaaS is a system that enables developers to compose, debug and deploy applications, using their organizations’ own data centers plus whatever public compute or storage they may require. Our Virginia Backaitis sees the open source Cloud Foundry PaaS as monumental, though some analysts are saying that Red Hat’s OpenShift may have grown past the point of parity with Cloud Foundry.
Both of these PaaS platforms are in the midst of huge architectural transitions between the unique systems they originally developed for themselves, and all-out support for Docker and containerization. It has meant fundamental transformations in how they work, but both camps see these shifts as vital to their platforms’ survival.
These platforms are designed to run applications that were designed with the intent of running on these platforms, which means they’re not designed to “containerize” or otherwise “virtualize” applications from the outside world.
But those applications that do run there are intended to be orchestrated internally, or using tools and resources supplied by the platforms themselves. Kubernetes (introduced in Part 1) can run with both OpenShift and Cloud Foundry, leading some to wonder whether orchestration can, or should, have two stages.
Red Hat has been playing with the idea of two stages, suggesting that its PaaS platform performs a job called “choreography.” I personally think it’s a poor choice of words, because “choreography” in reality implies that applications must work together by design.
Given the variety of things that must be coordinated to work together in a data center, I don’t believe that’s possible. Applications must be orchestrated in such a way that they co-exist. But the way programs are written — both for VMware-style and Docker-style environments — this may be the most we can expect for now.
 Learn how you can join our contributor community.
Learn how you can join our contributor community.
Scott M. Fulton III has been an editor and producer of online news and educational materials and author of instructional books and multimedia since 1984. Connect with Scott M. Fulton III: 
