Feature
Research Report
Building the Case for Modern Public Sector Messaging


Large language models (LLMs) are advanced artificial intelligence (AI) systems that can understand and generate human-like text — and their importance in today’s digital landscape can’t be overstated.
As we continue to see breakthroughs in machine learning (ML) and natural language processing (NLP), these sophisticated models are not just mimicking human-like conversation and content creation, but aiding in critical decision-making processes, powering advanced customer service, transforming the educational landscape and pushing the boundaries of creativity.
Large language models are powerful artificial intelligence models designed to comprehend, generate and engage in human language. They can read, understand and produce text that's often imperceptible from a person's. They're called "large" because of the vast amounts of data they're trained on and their expansive neural networks.
One of the most popular large language models available today is OpenAI's ChatGPT, which reached one million users within five days — a record in the tech world.

Related Article: ChatGPT: Your Comprehensive Guide
Prior to 2017, machines used a model based on recurrent neural networks (RNNs) to comprehend text. This model processed one word or character at a time and didn't provide an output until it consumed the entire input text. It was promising, but the models sometimes "forgot" the beginning of the input text before it reached the end.
In 2017, computer scientist Ashish Vaswani and fellow researchers published the paper, "Attention Is All You Need," introducing their new simple network architecture, the Transformer model.
The Transformer architecture processes words in relation to all other words in a sentence, rather than one-by-one in order. It's what allows these models to understand and generate coherent, contextually relevant responses.

LLMs are trained using a technique called "unsupervised learning." They're exposed to an enormous corpus of training data — books, articles, websites and more that are not categorized in any way — and are left to identify and learn the rules of language by themselves.
OpenAI's GPT-3, for example, (with GPT meaning Generative Pretrained Transformer) was trained on 570 gigabytes of data from books, webtexts, Wikipedia articles, Reddit posts and more. Or, exactly 300 billion words.
The training process involves predicting the next word in a sentence, a concept known as language modeling. This constant guesswork, performed on billions of sentences, helps models learn patterns, rules and nuances in language. They pick up grammar, syntax, content, cultural references, idioms, even slang. In essence, they learn how humans speak in their daily lives.
What's impressive about large language models is their generation capabilities. Once trained, they can apply their language understanding to tasks they were never explicitly trained for, ranging from writing essays to coding to translating languages.
Still, while large language models excel in understanding and generating human-like text, they don't possess comprehension the same way humans do. They don't "understand" or "think" about their responses. Their abilities stem from pattern recognition and statistical associations they've learned during training.
Related Article: AI & ChatGPT: Do You Trust Your Data?
There is no one large language model to rule them all. Instead, LLMs branch across multiple types or categories.
Note: These categories aren't mutually exclusive. Many large language models use a combination of approaches to maximize their understanding and usefulness.
The applications of large language models span across industries and tasks. Some of the most prominent uses of LLMs include:
The most common large language model examples are chatbots. LLMs power web interface chatbots that can deliver instant, round-the-clock responses — which makes it no surprise that they've become popular in retail and ecommerce spaces. They handle FAQs, troubleshoot issues and perform tasks like bookings and order processing.
But the use of these AI chatbots extends beyond retail. They're used by marketers to optimize content for search engines, by employers to offer personal tutors to employees. They assist researchers, financial advisers, legal teams and more.
Related Article: Generative AI Is Redefining Marketing Roles
As we marvel at the linguistic prowess of large language models and the exciting range of applications they can support, it's equally important to spotlight the challenges and limitations they present.
LLMs are remarkably good at mimicking human-like text generation. They can produce grammatically correct, contextually relevant and often meaningful responses. But these language models don't truly understand the text they process or generate. Their skills lie in detecting and applying patterns from their training data.
If you ask ChatGPT about its opinion on the movie "Titanic," for example, it can't provide a genuine response, because it doesn't watch movies or form opinions. Instead, it will generate a response based on patterns from its training data.
Hallucinations are essentially when LLMs "make up" information. They generate text that's not present in the input and not a reasonable inference from it. And they often present that information as fact, making it the user's responsibility to re-check information.
This issue presents challenges in a world where accuracy and truthfulness of information are critical. It's an area of ongoing research to devise ways to minimize such hallucinations without stifling the tech's creative and generative abilities.
Training LLMs is computationally intensive, requiring a substantial amount of processing power and energy. This can lead to high financial costs and environmental impact.
Researchers estimate that it cost OpenAI $5 million to train GPT-3. And that hefty price tag came from:
The amount of money and resources needed to train these large language models ultimately limits which people or organizations can invest in and possess them, potentially leading to imbalances in who develops and benefits from LLMs.
The saying "garbage in, garbage out" applies to large language models. These models are as good as the data they're trained on. If the training data lacks quality or diversity, the models can generate inaccurate, misleading or biased outputs.
For example, if a large language model is trained predominantly on data from a particular region or demographic group, its responses may be biased toward that group's perspective and may not accurately reflect or respect the diversity of human experiences and perspectives.
LLMs learn from a vast range of internet texts, which means they can inadvertently learn and reproduce the biases present in those texts. They might generate content that's inappropriate or offensive, especially if prompted with ambiguous or harmful inputs.
It's an ongoing challenge to develop safeguards and moderation strategies to prevent misuse while maintaining the models' utility. Researchers and developers are focusing on this area to create large language models that align with ethical norms and societal values — a topic much debated by Elon Musk amid the creation of his company xAI.
Another of the many challenges of large language models — and many other AI models — is their opacity, or the so-called "black box" problem.
It's often hard for people, even the ones who design these language models, to understand how the models arrive at a particular decision or output. And this lack of transparency can be problematic in scenarios where it's important to understand the reasoning behind a decision — like a medical diagnosis or legal judgment.
LLMs are trained on vast amounts of data, some of which might be sensitive, private or copyrighted. In fact, many writers and artists are attempting to sue LLM creators like OpenAI, claiming the companies trained their models on copyrighted works.
While most large language models are designed to generalize patterns from data rather than memorize specific information, there's a risk they could inadvertently generate text or image outputs that resemble private or sensitive information.
Despite significant advancements, the development and application of large language models remains a complex process.
From selecting the appropriate model architecture and hyperparameters for training, to fine-tuning the model for specific applications and even interpreting the model's outputs, a certain degree of technical expertise is required. This complexity can pose a barrier for organizations looking to develop or utilize these models.
Glitch tokens are tokens (chunks of text, essentially) that trigger unexpected or unusual behavior in large language models. These tokens can provoke unexpected or unusual behavior in a model, sometimes leading to outputs that are random, nonsensical or entirely unrelated to the input text.
One internet user, for example, discovered back in April that GPT-3 had an issue repeating back the phrase "petertodd" — with "petertodd" being the glitch token. Instead, it responded by spelling out silly phrases, like "N-U-T-M-A-N" and "N-O-T-H-I-N-G-I-S-F-A-I-R-I-N-T-H-I-S-W-O-R-L-D-O-F-M-A-D-N-E-S-S-!"
While glitch tokens like the Petertodd Phenomenon don't pose any meaningful threat, understanding them will help researchers make LLMs more reliable tools for a wider variety of applications.
Large language models have emerged as a pivotal innovation in the field of artificial intelligence, underscoring a leap in the way machines understand and generate human language. Their importance is rooted in their versatility, scale and potential to redefine various domains.
What stands out for LLMs is:
Despite their current limitations and challenges, the importance of large language models can't be understated. They signal a shift toward a future where seamless human-machine communication could become commonplace, and where technology doesn't just process language — it understands and generates it.
Related Article: Generative AI: Exploring Ethics, Copyright and Regulation
Large language models have the potential to significantly reshape our interactions with technology, driving automation and efficiency across sectors.
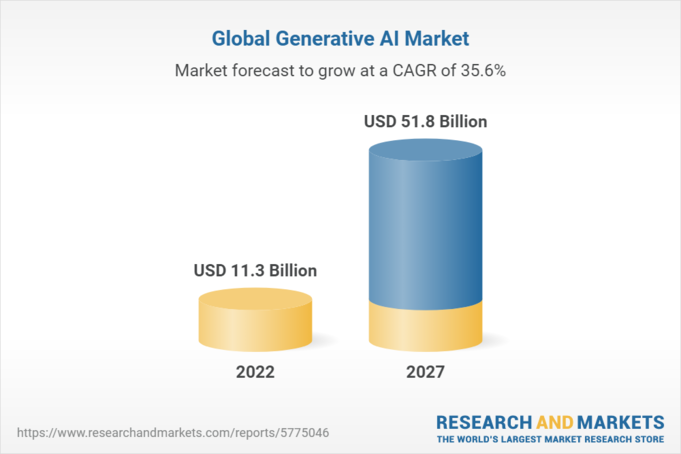
The generative AI market, which LLMs fall under, is expected to see rapid growth in the coming years, rising from $11.3 billion in 2023 to $51.8 billion by 2028, with a compound annual growth rate of 35.6%.
With ongoing research aimed at overcoming the limitations of LLMs, the day might not be far when these models understand natural language with near-human levels of nuance and comprehension and take part in all aspects of our daily lives.