Editorial
Research Report
Building the Case for Modern Public Sector Messaging


Of the 175 product and service announcements at this year’s Microsoft Ignite Conference, none was more impactful for information managers than the launch of Project Cortex.
The announcement states: “Project Cortex is a new service in Microsoft 365 that … uses AI to automatically classify all your content into topics to form a knowledge network .... It empowers people and teams with knowledge, learning, and expertise, in the flow of their everyday work … [and it] improves individual productivity and organizational intelligence, helping identify experts on specific topics, and surfacing knowledge through interactive experiences across Microsoft 365, such as in the Office apps, Outlook, and Microsoft Teams.”
In short, Cortex purports to organize your emails, documents and meeting recordings, and group this information by topics, so you focus on your work; what I call “topic computing.” I have been predicting an age of topic computing for several years as a practical solution to acute information overload, namely organizing all of our "stuff" the way the brain works so we can focus on what really matters most. People intuitively think in terms of topics like projects, products, services and customers rather than documents, emails and tasks. So presenting information by topics not only increases productivity, it also reduces the stress associated with information overload. As a brain-like way of presenting information, Cortex is an appropriate name for this initiative.
Of course, Microsoft didn’t invent topic computing, nor did it come up with the idea of presenting information the way the brain works. The idea is as old as Aristotle.
In more modern times, FDR’s chief scientific advisor, Vannevar Bush, espoused such an approach back in 1945 as a way to deal with the information overload he experienced emanating from an explosion of professional articles and correspondence. Bush envisioned a device to organize information by topics, which he called Memex. Bush’s "invention" consisted of a desk that incorporated a book the user would use to build an index of interesting topics. The user would photocopy, record (initially voice and later video), or type text into the Memex interface, whereupon it would be captured into the record. The user would then assign each piece of content a set of topics (think metadata) and the topics would be added to the index. Later, when the user would select a topic from the index, they could locate related content which was stored on microfilm.
The Memex was never built, although several attempts have been made over the years to refine the device concept using newer technologies. Ultimately, its success relied upon a massive amount of user input and the user experience was too complicated to derive real value. Plus, the Memex was a personal device. There was no uniform or standard way to define or share common topics.
Related Article: Vannevar Bush Points the Way to a New Era of Computing
As businesses began to operate as networked organizations, the sources of information overload shifted from journals, letters and memos, to shared content like emails, documents and tasks. So the need to assimilate collective information, in addition to individual content, exacerbated the problem of overload. In today’s workplace, productivity has largely become a collective goal rather than a personal achievement, so a solution to overload must address the group as well as the individual.
Different attempts to organize information by topics have been tried over the years but ultimately failed because of technical difficulties. Some of these hurdles include the following:
Related Article: Information Overload Comes in 3 Flavors: Here's How to Combat It
New opportunities to manage information by topics have opened as new technologies made their way into the workplace. Specifically, the introduction of the cloud as an infrastructure for shared data across many applications, and the advent of practical AI — in the form of natural language processing and machine learning — create a new reality for information managers. For the first time, business content can be aggregated into a single place: the data cloud.
The aggregation of data into a single location also enables the exploitation of a data graph, which is a construct for capturing and detailing relationships between content and people. Facebook and Google have built data graphs for the consumer market, and now the Microsoft Graph captures the relationships between business people and their content, like email, documents, tasks, events, photos and more. It captures the authors of content, and it tracks who is editing and sharing the content. As a result, the graph can also register usage information like what content is popular.
Related Article: Will Microsoft Graph Deliver on the Promises of the Social Graph?
Microsoft has developed the infrastructure components needed to address the technical challenges that previously inhibited topic computing. It has solved the aggregation and standardization of data storage challenge by storing each person’s documents, emails, tasks, events, photos, and all other pieces of business information into a single location, the Office 365 cloud. The Microsoft Graph provides the connections between people and content. And finally, Microsoft can tap the consumer AI experience harvested from 10 years of Bing search experience in the consumer market, experience it can now bring to bear to ferret out topics embedded in unstructured emails, documents and other artifacts.
Putting all the pieces together, the recently announced Project Cortex purports to build a knowledge graph of enterprise topics, showing how the topics people are working on are logically connected, as show in the figure below.
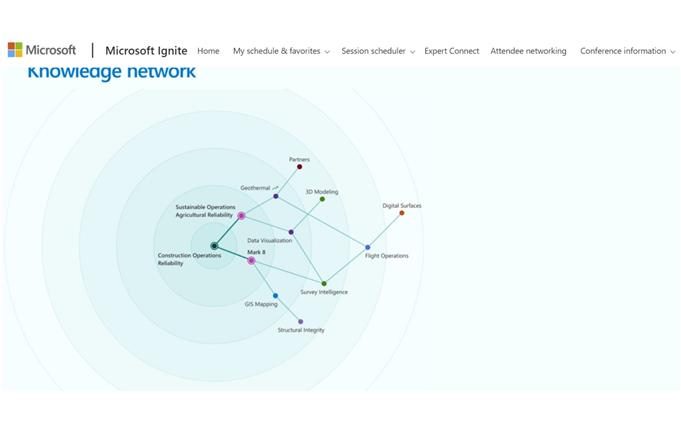
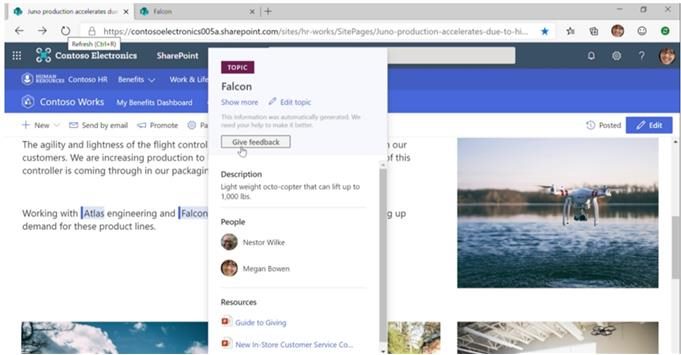
Using the intelligence of this graph, Cortex claims to tie content to topics like the name of a customer or product, and to present all the information related to that customer or product in a single "topic card," as seen in the graphic below, as well as to point out related topics.
Project Cortex was detailed in a number of keynote addresses and technical sessions at Ignite 2019. If it works as advertised — and that's a big IF — Cortex may forever change the way we work. Microsoft has announced general worldwide availability of this technology in the first half of 2020, which doesn’t seem like enough time to go from concept to fully baked service, especially one of this magnitude.
Related Article: Microsoft Graph Data Connect: The Glue That Binds Office 365 and Azure
According to Microsoft spokespeople, Cortex has been under development as a secret project for the last two years. As per information presented at the conference, it has been tested within Microsoft and has begun testing at Mott McDonald, a global consulting company, which was the sole customer reference included in the product announcement.
Currently, no packaging or pricing details are available for Cortex.
One of the big questions for Cortex is how much human intervention will be needed to identify important topics within an organization? At one of the Ignite technical sessions, it was suggested that human topic curation (what Microsoft is calling "light editing") is helpful, but not necessary, for topic extraction and identification.
How well a fully automated system would work is unclear. Yet if the system depends on people in the organization to pinpoint interesting topic terms, adoption will be much slower. Asking users to identify topic terms, filter out bad topics, and augment details about the topic is challenging. It remains to be seen if employees will cooperate. While Microsoft may call the task light editing, it doesn't appear any lighter than applying metadata when capturing documents to shared repositories like SharePoint, which we've seen has been a futile effort. Workers are rarely eager to take the extra steps of attaching tags to content when saving documents while in the flow of a business process, regardless of the value they may derive later. From one of the demos presented at the conference, curating topics doesn’t appear any easier than applying metadata — so the user experience will be a critical factor in Cortex’s success.
Related Article: Managing Metadata: Any Volunteers?
Topic computing presents a paradigm shift in how we help people focus on what matters most in the workplace. Project Cortex offers enormous potential for dealing with information overload at work. As such, there is a huge incentive to get it right.
On the other hand, the 2020 release schedule seems a bit ambitious. It is reasonable to assume Microsoft will need additional experience with more diverse customer experiences to develop a satisfactory offering for the broad market.
 Learn how you can join our contributor community.
Learn how you can join our contributor community.
David is a Technical Innovation Strategist and Product-Market Fit Expert who has helped dozens of young technology companies turn complex ideas into winning products. Concurrently, he is pursuing a PhD in Science, Technology, and Society, exploring how strategies for knowledge organization evolve during information revolutions, like the current AI era.